This set of Machine Learning Multiple Choice Questions & Answers (MCQs) focuses on “Soft SVM and Norm Regularization”.
1. The Soft SVM assumes that the training set is linearly separable.
a) True
b) False
View Answer
Explanation: The Soft SVM did not assume that the training set is linearly separable. But the Hard SVM assumes that the training set is linearly separable. And Soft SVM can be applied even if the training set is not linearly separable.
2. Soft SVM is an extended version of Hard SVM.
a) True
b) False
View Answer
Explanation: Soft SVM is an extended version of Hard SVM. Hard SVM can work only when data is completely linearly separable without any errors (noise or outliers). If there are errors then either the margin is smaller or hard margin SVM fails. And Soft SVM was proposed to solve this problem by introducing slack variables.
3. Linear Soft margin SVM can only be used when the training data are linearly separable.
a) True
b) False
View Answer
Explanation: The Linear Soft margins SVM are not used when the training data are linearly separable but can use Hard SVM only. Because linear separability of the training data is a strong assumption in Hard SVM. And Soft SVM can be applied if the training set is not linearly separable.
4. Given a two-class classification problem with data points x1 = -5, x2 = 3, x3 = 5, having class label +1 and x4 = 2 with class label -1. The problem can be solved using Soft SVM.
a) True
b) False
View Answer
Explanation: The given problem is a one dimensional two-class classification problem. Here the points x1, x2, and x3 have class labels +1 and x4 has class label -1. And the dataset is not linearly separable, so we can use Soft SVM to solve this classification problem.
5. Given a two-class classification problem with data points x1 = -5, x2 = 3, x3 = 5, having class label +1 and x4 = 2 with class label -1. The problem can never be solved using Hard SVM.
a) True
b) False
View Answer
Explanation: The given problem is a one dimensional two-class classification problem and the data points are non-linearly separable. So the problem cannot be solved by the Hard SVM directly. But it can be solved using Hard SVM if the one dimensional data set is transformed into a 2-dimensional dataset using some function like (x, x2). Then the problem is linearly separable and can be solved by Hard SVM.
6. Which of the following statements is not true about the picture shown below?
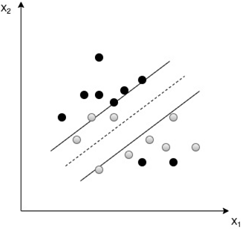
a) The data are not completely separable
b) Slack variables can be introduced to the objective function to allow error in the misclassification
c) Soft SVM can be used here to classify the data correctly
d) Hard SVM can be used here to classify the data flawlessly
View Answer
Explanation: Here we cannot use Hard SVM to classify the data flawlessly, because the data are not completely separable. But we can use Soft SVM for the same classification purpose. And can introduce slack variables to the SVM objective function to allow the error in the misclassification.
7. The SVM relies on hinge loss.
a) True
b) False
View Answer
Explanation: The SVM relies on hinge loss. Because hinge loss is convex and, therefore minimizing the hinge loss can be performed efficiently. But the problem of minimising the other losses is computationally intractable.
8. Which of the following statements is not true about Soft SVM classification?
a) If the data are non separable it needs to introduce some tolerance to outlier data points
b) If the data are non separable, slack variable can be added to allow misclassification of noisy examples
c) If the data are non separable it will add one slack variable greater than or equal to zero for each training data point
d) The slack variable value is greater than one for the points that are on the correct side of the margin
View Answer
Explanation: The slack variable value is equal to zero for the points that are on the correct side of the margin. And if the data are non-separable it introduces some tolerance to outlier data points (slack variable). And the value of the slack variable will be greater than or equal to zero.
9. The slack variable value of the point on the decision boundary of the Soft SVM is equal to one.
a) True
b) False
View Answer
Explanation: The slack variable value of the point on the decision boundary of the Soft SVM is equal to one. Slack variables are introduced to allow certain constraints to be violated. That is, certain training points will be allowed to be within the margin.
10. The slack variables value ξi ≥ 1 for misclassified points, and 0 < ξi < 1 for points close to the decision boundary.
a) True
b) False
View Answer
Explanation: The slack variables ξi ≥ 1 for misclassified points, and 0 < ξi < 1 for points close to the decision boundary. For non separable data it aims to both maximize the margin and minimize violation of the margin constraints. So one slack variable ξ must be optimized for each data point.
11. The bounds derived for Soft-SVM do not depend on the dimension of the instance space.
a) True
b) False
View Answer
Explanation: The bounds derived for Soft-SVM do not depend on the dimension of the instance space. The bounds depend on the norm of the examples, the norm of the half-space. And in the non-separable case, the bounds also depend on the minimum hinge loss of all half-spaces of norm less than or equal to half-space.
Sanfoundry Global Education & Learning Series – Machine Learning.
To practice all areas of Machine Learning, here is complete set of 1000+ Multiple Choice Questions and Answers.
If you find a mistake in question / option / answer, kindly take a screenshot and email to [email protected]
