This set of Machine Learning Multiple Choice Questions & Answers (MCQs) focuses on “Random Forest Algorithm”.
1. Random forest can be used to reduce the danger of overfitting in the decision trees.
a) True
b) False
View Answer
Explanation: One way to reduce the danger of overfitting is by constructing an ensemble of trees. So Random forest is an ensemble method which is better than a single decision tree because it reduces the over-fitting by averaging the result.
2. Which of the following statements is not true about the Random forests?
a) It is a classifier consisting of a collection of decision trees
b) Each tree is constructed by applying an algorithm on the training set and an additional random vector
c) The prediction of the random forest is obtained by a majority vote over the predictions of the individual trees
d) Each individual tree in the random forest will not spits out a class prediction
View Answer
Explanation: As Random forest is a classifier consisting of a collection of decision trees, each individual tree in the random forest spits out a class prediction and the class with the most votes becomes the model’s prediction. And each tree is constructed by applying an algorithm on the training set and an additional random vector.
3. Which of the following statements is not true about the Random forests?
a) It is an ensemble learning method for classification only
b) It operates by constructing a multitude of decision trees at training time
c) It outputs the class that is the mode of the classes
d) It outputs the mean prediction of the individual trees
View Answer
Explanation: Random forest is a supervised learning method which are used for classification and regression. It is a group of decision trees. The more the number of the trees the result is error-free. During training time multitude of decision trees will be constructed.
4. Which of the following statements is not true about Random forests?
a) Scaling of data required in random forest algorithm
b) It works well for a large range of data items than a single decision tree
c) It has less variance than single decision tree
d) Random forests are very flexible and possess very high accuracy
View Answer
Explanation: Scaling of data does not require in random forest algorithm. It maintains good accuracy and it is very flexible even after providing data without scaling. It works well for a large range of data items and has less variance than a single decision tree.
5. Which of the following statements is not true about Random forests?
a) It has high complexity
b) Construction of Random forests are much easier than decision trees
c) Construction of Random forests are time-consuming than decision trees
d) More computational resources are required to implement Random Forest algorithm
View Answer
Explanation: Construction of Random forests is much harder and time-consuming than decision trees as it requires more computational resources for the implementation. And it has high complexity.
6. There is a direct relationship between the number of trees in the random forest and the results.
a) False
b) True
View Answer
Explanation: Random forest is a supervised machine learning technique. And there is a direct relationship between the number of trees in the forest and the results it produces. If larger the number of trees, the result will be more accurate.
7. A data set T is split into two subsets T1 and T2 with sizes N1 and N2. And Gini index of the split data contains examples from N classes. Then the Gini index of T is defined by which of the following options?
a) Ginisplit (T) = \(\frac {N_2}{N}\) gini (T1) + \(\frac {N_1}{N}\) gini (T2)
b) Ginisplit (T) = \(\frac {N}{N_1}\) gini (T1) + \(\frac {N}{N_2}\) gini (T2)
c) Ginisplit (T) = \(\frac {N}{N_2}\) gini (T1) + \(\frac {N}{N_1}\) gini (T2)
d) Ginisplit (T) = \(\frac {N_1}{N}\) gini (T1) + \(\frac {N_2}{N}\) gini (T2)
View Answer
Explanation: Let a data set T is split into two subsets T1 and T2 with sizes N1 and N2. And Gini index of the split data contains examples from N classes. Then the Gini index of T is defined by, Ginisplit (T) = \(\frac {N_1}{N}\) gini (T1) + \(\frac {N_2}{N}\) gini (T2). And its implementation is not easy as a decision tree with impurity measures.
8. Random forest is known as the forest of Decision trees.
a) True
b) False
View Answer
Explanation: Random forest makes predictions by combining the results from many individual decision trees. So, we call them a forest of decision trees. Random forest combines multiple models, and it falls under the category of ensemble learning.
9. Bagging and Boosting are two main ways for combining the outputs of multiple decision trees into a random forest.
a) True
b) False
View Answer
Explanation: Bagging and Boosting are two main ways for combining the outputs of multiple decision trees into a random forest. Bagging is also called Bootstrap aggregation (used in Random Forests) and Boosting (used in Gradient Boosting Machines).
10. Which of the following is represented by the below figure?
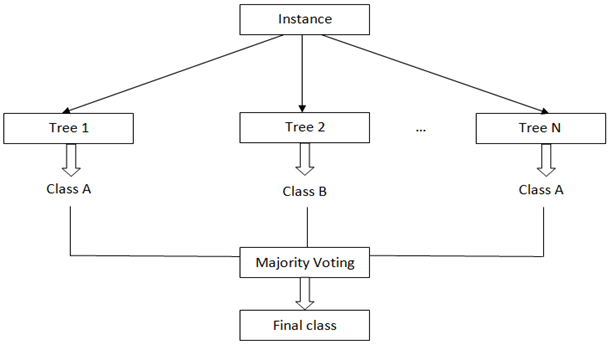
a) Support vector machine
b) Random forest
c) Regression tree
d) Classification tree
View Answer
Explanation: The given figure shows the Random forest where the outputs of multiple decision trees are combined to form a random forest. And the final result of the model is calculated by averaging over all predictions from these sampled trees or by majority vote.
11. Suppose we are using a random forest algorithm to solve regression problem and there are 4 data points. The value returned by the model and the actual value for the data points 1, 2, 3, and 4 are 11, 14, 9, 10 and 8, 10, 12, 14 respectively. What is the mean squared error?
a) 11.5
b) 14
c) 12.5
d) 10
View Answer
Explanation: We know the mean squared error MSE = \(\frac {1}{N}\) ∑\(_{i=1} ^N\)(fi – yi)2
Given N = 4, f1 = 11, f2 = 14, f3 = 9, f4 = 10, y1 = 8, y2 = 10, y3 = 12 and y4 = 14
MSE = \(\frac {1}{4}\) ((11-8)2 + (14-10)2 + (9-12)2 +(10-14)2)
= \(\frac {1}{4}\) ((3)2 + (4)2 + (-3)2 + (-4)2))
= \(\frac {1}{4}\) (9 + 16 + 9 + 16)
= 504
= 12.5
12. Consider we are performing Random Forests based on classification data, and the relative frequencies of the class you are observing in the dataset are 0.65, 0.35, 0.29 and 0.5. What is the Gini index?
a) 0.423
b) 0.084
c) 0.12
d) 0.25
View Answer
Explanation: We know Gini index = 1 – ∑\(_{i=1} ^c\)(pi)2 where pi represents the relative frequency of the class you are observing in the dataset and c represents the number of classes. And we have p1 = 0.65, p2 = 0.35, p3 = 0.29 and p4 = 0.5
Gini index = 1 – (0.652 + 0.352 + 0.292 + 0.52)
= 1 – (0.423 + 0.123 + 0.084 + 0.25)
= 1 – 0.88
= 0.12
Sanfoundry Global Education & Learning Series – Machine Learning.
To practice all areas of Machine Learning, here is complete set of 1000+ Multiple Choice Questions and Answers.
If you find a mistake in question / option / answer, kindly take a screenshot and email to [email protected]
