This set of Machine Learning Multiple Choice Questions & Answers (MCQs) focuses on “Large Margin Intuition”.
1. The goal of a support vector machine is to find the optimal separating hyperplane which minimizes the margin of the training data.
a) False
b) True
View Answer
Explanation: The goal of a support vector machine is to find the optimal separating hyperplane which maximizes the margin of the training data. So it is based on finding the hyperplane that gives the largest minimum distance to the training examples.
2. Which of the following statements is not true about hyperplane in SVM?
a) If a hyperplane is very close to a data point, its margin will be small
b) If an hyperplane is far from a data point, its margin will be large
c) Optimal hyperplane will be the one with the biggest margin
d) If we select a hyperplane which is close to the data points of one class, then it generalize well
View Answer
Explanation: If we select a hyperplane which is close to the data points of one class, then it might not generalize well. If a hyperplane is very close to a data point, its margin will be small and if it is far from a data point, its margin will be large. So the optimal hyperplane is the one with the biggest margin.
3. Which of the following statements is not true about optimal separating hyperplane?
a) It correctly classifies the training data
b) It is the one which will generalize better with unseen data
c) Finding the optimal separating hyperplane can be formulated as a convex quadratic programming problem
d) The optimal hyperplane cannot correctly classifies all the data while being farthest away from the data points
View Answer
Explanation: The optimal hyperplane correctly classifies all the data while being farthest away from the data points. So it correctly classifies the training data and will generalize better with unseen data. And finding the optimal separating hyperplane can be formulated as a convex quadratic programming problem.
4. Support Vector Machines are known as Large Margin Classifiers.
a) True
b) False
View Answer
Explanation: SVM is a type of classifier which classifies sample data. And the largest margin is found in order to avoid overfitting and the optimal hyperplane is at the maximum distance from the samples. So the margin is maximized to classify the data points accurately.
5. Which of the following statements is not true about the role of C in SVM?
a) The C parameter tells the SVM optimisation how much you want to avoid misclassifying each training example
b) For large values of C, the optimisation will choose a smaller-margin hyperplane
c) For small values of C, the optimisation will choose a large-margin hyperplane
d) If we increase margin, it will end up getting a low misclassification rate
View Answer
Explanation: If we increase margin, it will end up getting a high misclassification rate. Because the C parameter tells the SVM optimisation how much you want to avoid misclassifying each training example. For large values of C, the optimisation will choose a smaller-margin hyperplane and vice versa.
6. Which of the following statements is not true about large margin intuition classifier?
a) It has a hyperplane with the maximum margin
b) The hyperplane divides the data properly and is as far as possible from your data points
c) The hyperplane is close to your data points
d) When new data comes in, even if it is a little closer to the wrong class than the training points, it will still lie on the right side of the hyperplane
View Answer
Explanation: The hyperplane is not close to your data points but is as far as possible from it. In large margin intuition classifier the hyper plane is with a maximum margin. So when new data comes in, even if it is a little closer to the wrong class than the training points, it will still lie on the right side of the hyperplane.
7. Suppose the optimal separating hyperplane is given by 2x1 + 4x2 + x3 − 4 = 0 and the class labels are +1 and -1. For the training example (1, 0.5, 1), the class label is -1, and is a support vector.
a) True
b) False
View Answer
Explanation: Suppose the optimal separating hyperplane is given by 2x1 + 4x2 + x3 − 4 = 0 and the class labels are +1 and -1. For the training example (1, 0.5, 1), the class label is +1, and is a support vector.
Let the training sample is (1, 0.5, 1) and the optimal separating hyperplane is given by 2x1 + 4x2 + x3 − 4 = 0.
2x1 + 4x2 + x3 − 4 = 2 * 1 + 4 * 0.5 + 1 − 4
= 2 + 2 + 1 – 4
= 5 – 4
= +1
8. The optimum separation hyperplane (OSH) is the linear classifier with the minimum margin.
a) True
b) False
View Answer
Explanation: The optimum separation hyperplane (OSH) is the linear classifier with the maximum margin for a given finite set of learning patterns. To find the OSH draw convex hull around each set of points and find the shortest line segment connecting two convex hulls. Find midpoint of line segment and the optimal hyperplane is perpendicular to segment at midpoint of line segment.
9. SVM find outs the probability value.
a) True
b) False
View Answer
Explanation: SVM does not find out the probability value. Suppose you are given a set of training examples, each marked as belonging to one of two categories, an SVM training algorithm builds a model that assigns new examples into one category or the other, making it a non probabilistic binary classifier.
10. Given figure shows some data points classified by an SVM classifier and the bold line on the center represents the optimal hyperplane. What the perpendicular distance between the two dashed lines represented by a double arrow line known as?
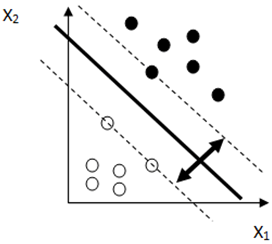
a) Maximum margin
b) Minimum margin
c) Support vectors
d) Hyperplane
View Answer
Explanation: The operation of the SVM algorithm is based on finding the optimal hyperplane. Therefore, the optimal separating hyperplane maximizes the margin of the training data. And hence the distance between the two dashed lines are known as maximum margin.
11. What is the leave-one-out cross-validation error estimate for maximum margin separation in the following figure?
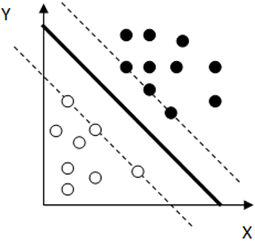
a) Zero
b) Maximum
c) Minimum
d) Half of the previous error value
View Answer
Explanation: From the figure we can see that removing any single point would not chance the resulting maximum margin separator. Here all the points are initially classified correctly, so the leave-one-out error is zero.
Sanfoundry Global Education & Learning Series – Machine Learning.
To practice all areas of Machine Learning, here is complete set of 1000+ Multiple Choice Questions and Answers.
If you find a mistake in question / option / answer, kindly take a screenshot and email to [email protected]
