This set of Machine Learning Multiple Choice Questions & Answers (MCQs) focuses on “Margin and Hard SVM”.
1. In SVM the distance of the support vector points from the hyperplane are called the margins.
a) True
b) False
View Answer
Explanation: The SVM is based on the idea of finding a hyperplane that best separates the features into different domains. And the points closest to the hyperplane are called as the support vector points and the distance of the vectors from the hyperplane are called the margins.
2. If the support vector points are farther from the hyperplane, then this hyperplane can also be called as margin maximizing hyperplane.
a) True
b) False
View Answer
Explanation: In SVM if more the farther support vector points, from the hyperplane, then this hyperplane can also be called as margin maximizing hyperplane. And the probability of correctly classifying the points in their respective region or classes is high.
3. Which of the following statements is not true about the C parameter in SVM?
a) Large values of C give solutions with less misclassification errors
b) Large values of C give solutions with smaller margin
c) Small values of C give solutions with bigger margin
d) Small values of C give solutions with less classification errors
View Answer
Explanation: Small values of C give solutions with more classification errors but a bigger margin. So it focuses more on finding a hyperplane with a big margin. And large values of C give solutions with less misclassification errors but a smaller margin.
4. Which of the following statements is not true about margin in SVM?
a) The margin of a hyperplane with respect to a training set is defined to be the minimal distance between a point in the training set and the hyperplane
b) The margin of a hyperplane with respect to a training set is defined to be the maximum distance between a point in the training set and the hyperplane
c) If a hyperplane has a large margin, then it will still separate the training set even if we slightly disturb each instance
d) True error of a half space can be bounded in terms of the margin that it has over the training sample
View Answer
Explanation: The margin of a hyperplane with respect to a training set is defined to be not the maximum but the minimal distance between a point in the training set and the hyperplane. So if a hyperplane has a large margin, then it will still separate the training set even if we slightly disturb each instance. And the true error of a half space can be bounded in terms of the margin it has over the training sample.
5. The maximum margin linear classifier is the linear classifier with the maximum margin.
a) True
b) False
View Answer
Explanation: The maximum margin linear classifier is the linear classifier with the maximum margin. And these kinds of SVMs are called Linear SVM (LSVM). Support vectors are those data points that the margin pushes up against.
6. Which of the following statements is not true about maximum margin?
a) It is safe and empirically works well
b) It is not sensitive to removal of any non support vector data points
c) If the location of the boundary is not perfect due to noise, this gives us the least chance of misclassification
d) It is not immune to removal of any non-support-vector data points
View Answer
Explanation: The maximum margin is immune to removal of any non support vector data points. It is safe and empirically works well. So even If we have made a small error in the location of the boundary (imperfect location of the boundary) this gives us least chance of causing a misclassification.
7. Hard SVM is the learning rule in which return an ERM hyperplane that separates the training set with the largest possible margin.
a) True
b) False
View Answer
Explanation: Hard-SVM is the learning rule in which return an ERM hyperplane that separates the training set with the largest possible margin. Here the margin of an ERM hyperplane with respect to a training set is defined to be the minimal distance between a point in the training set and the ERM hyperplane.
8. The output of hard-SVM is the separating hyperplane with the largest margin.
a) True
b) False
View Answer
Explanation: The output of hard-SVM is the separating hyperplane with the largest margin and it seeks for the separating plane with the largest margin. Hard-SVM works on separable problems and it finds the linear predictor with the maximal margin on the training sample.
9. Assume that we are training an SVM with quadratic kernel. Given figure shows a dataset and the decision boundary will be the one with maximum curvature for very large values of C as shown in figure.
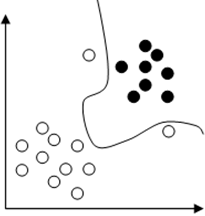
a) True
b) False
View Answer
Explanation: The slack penalty C will determine the location of the separating parabola. When C is too large, we can’t afford any misclassification. And hence among all the parabolas, it chooses the minimum curvature one. So the decision boundary will be the one with minimum curvature as shown below.
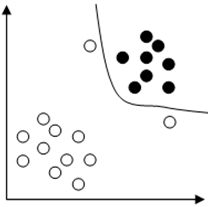
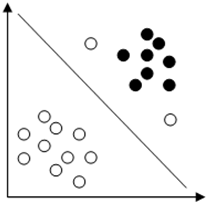
10. Assume that we are training an SVM with quadratic kernel. Given figure shows a dataset and the decision boundary will be the one with maximum curvature when values of C = 0 as shown in figure.
a) True
b) False
View Answer
Explanation: The slack penalty C will determine the location of the separating parabola. When the penalty for misclassification is too small (C = 0) the decision boundary will be linear. So the decision boundary will be like as shown below.
11. The given figure shows the hard margin while classifying a set of data points using SVM.
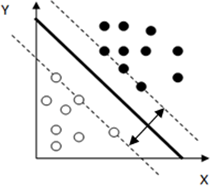
a) True
b) False
View Answer
Explanation: The given figure shows the hard margin while classifying a set of data points using SVM. Here all the points are correctly classified. And the hard margin maximizes margin between separating hyperplane.
Sanfoundry Global Education & Learning Series – Machine Learning.
To practice all areas of Machine Learning, here is complete set of 1000+ Multiple Choice Questions and Answers.
If you find a mistake in question / option / answer, kindly take a screenshot and email to [email protected]
