This set of Machine Learning Multiple Choice Questions & Answers (MCQs) focuses on “Ensemble Learning – Model Combination Schemes”.
1. Which of the following statements is false about Ensemble learning?
a) It is a supervised learning algorithm
b) More random algorithms can be used to produce a stronger ensemble
c) It is an unsupervised learning algorithm
d) Ensembles can be shown to have more flexibility in the functions they can represent
View Answer
Explanation: Ensemble learning is not an unsupervised learning algorithm. It is a supervised learning algorithm that combines several machine learning techniques into one predictive model to decrease variance and bias. It can be trained and then used to make predictions. And this ensemble can be shown to have more flexibility in the functions they can represent.
2. Ensemble learning is not combining learners that always make similar decisions; the aim is to be able to find a set of diverse learners.
a) True
b) False
View Answer
Explanation: Ensemble learning aims to find a set of diverse learners who differ in their decisions so that they complement each other. There is no point in combining learners that always make similar decisions.
3. Which of the following is not a multi – expert model combination scheme to generate the final output?
a) Global approach
b) Local approach
c) Parallel approach
d) Serial approach
View Answer
Explanation: Multi – expert combination methods have base – learners that work in parallel. Global approach and Local approach are the two subdivisions of this parallel approach. Serial approach is a multi – stage combination method.
4. The global approach is also known as learner fusion.
a) False
b) True
View Answer
Explanation: The global approach also called as learner fusion. Where given an input, all base – learners generate an output and all these outputs are combined by voting or averaging. This represents integration (fusion) functions where for each pattern, all the classifiers contribute to the final decision.
5. Which of the following statements is true about multi – stage combination methods?
a) The next base – learner is trained on only the instances where the previous base – learners are not accurate enough
b) It is a selection approach
c) It has base – learners that work in parallel
d) The base – learners are sorted in decreasing complexity
View Answer
Explanation: It is a serial approach; the next base – learner is trained or tested on only the instances where the previous base – learners are not accurate enough. A multi – stage combination method is neither a parallel approach nor a selection approach. The base – learners are sorted in increasing complexity.
6. Which of the following is not an example of a multi – expert combination method?
a) Voting
b) Stacking
c) Mixture of experts
d) Cascading
View Answer
Explanation: Cascading is not a multi – expert combination example and is a multi – stage combination method. It is based on the concatenation of several classifiers, which use all the information collected from the output from a given classifier as additional information for the next classifier in the cascade. Voting, stacking and a mixture of experts are the example of multi – expert combination methods.
7. Which of the following statements is false about the base – learners?
a) The base – learners are chosen for their accuracy
b) The base – learners are chosen for their simplicity
c) The base – learners has to be diverse
d) Base – learners do not require them to be very accurate individually
View Answer
Explanation: When we generate multiple base – learners, we want them to be reasonably accurate but do not require them to be very accurate individually. Hence the base – learners are not chosen for their accuracy, but for their simplicity. However, the base – learners have to be diverse.
8. Different algorithms make different assumptions about the data and lead to different classifiers in generating diverse learners.
a) True
b) False
View Answer
Explanation: Different algorithms make different assumptions about the data and lead to different classifiers. For example one base – learner may be parametric and another may be nonparametric. When we decide on a single algorithm, we give importance to a single method and ignore all others.
9. Ensembles tend to yield better results when there is a significant diversity among the models.
a) False
b) True
View Answer
Explanation: Ensembles tend to yield better results when there is a significant diversity among the models. Many ensemble methods, therefore, try to promote diversity among the models they combine.
10. The partitioning of the training sample cannot be done based on locality in the input space.
a) False
b) True
View Answer
Explanation: The partitioning of the training sample can also be done based on locality in the input space. So each base – learner is trained on instances in a certain local part of the input space. And it is done by a mixture of experts.
11. Which of the following is represented by the below figure?
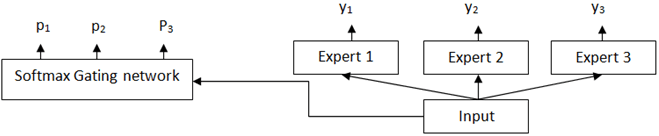
a) Stacking
b) Mixture of Experts
c) Bagging
d) Boosting
View Answer
Explanation: The figure shows a Mixture of Experts. It is based on the divide – and – conquer principle and mixture of experts trains individual models to become experts in different regions of the feature space. Then, a gating network decides which combination of ensemble learners is used to predict the final output of any instance.
12. Given the target value of a mixture of expert combinations is 0.8. The predictions of three experts and the probability of picking them are 0.6, 0.4, 0.5 and 0.8, 0.5, 0.7 respectively. Then what is the simple error for training?
a) 0.13
b) 0.15
c) 0.18
d) 0.2
View Answer
Explanation: We know the simple error for training:
E = ∑ipi(d – yi)2 where d is the target value and pi is the probability of picking expert i, and yi is the individual prediction of expert i. Given d = 0.8, y1 = 0.6, y2 = 0.4, y3 = 0.5 and p1 = 0.8, p2 = 0.5, p3 = 0.7
Then E = p1(d – y1)2 + p2(d – y2)2 + p3(d – y3)2
= 0.8(0.8 – 0.6)2 + 0.5(0.8 – 0.4)2 + 0.7(0.8 – 0.5)2
= 0.8(0.2)2 + 0.5(0.4)2 + 0.7(0.3)2
= 0.8 * 0.04 + 0.5 * 0.16 + 0.7 * 0.09
= 0.032 + 0.08 + 0.063
= 0.18
13. The ABC company has released their Android app. And 80 people have rated the app on a scale of 5 stars. Out of the total people 15 people rated it with 1 star, 20 people rated it with 2 stars, 30 people rated it with 3 stars, 10 people rated it with 4 stars and 5 people rated it with 5 stars. What will be the final prediction if we take the average of individual predictions?
a) 2
b) 3
c) 4
d) 5
View Answer
Explanation: Given that we are taking the average of individual predictions to make the final prediction.
Average = ∑ (Rating * Number of people) / Total number of people
= ((1 * 15) + (2 * 20) + (3 * 30) + (4 * 10) + (5 * 5)) / 80
= (15 + 40 + 90 + 40 + 25) / 80
= 210 / 80
= 2.625
And the nearest integer is 3. So the final prediction will be 3.
14. Consider there are 5 employees A, B, C, D, and E of ABC company. Where people A, B and C are experienced, D and E are fresher. They have rated the company app as given in the table. What will be the final prediction if we are taking the weighted average?
| Employee | Weight | Rating |
| A | 0.4 | 3 |
| B | 0.4 | 2 |
| C | 0.4 | 2 |
| D | 0.2 | 2 |
| E | 0.2 | 4 |
a) 2
b) 3
c) 4
d) 5
View Answer
Explanation: We have,
Weighted average = ∑ (Weight * Rating)
= (0.4 * 3) + (0.4 * 2) + (0.4 * 2) + (0.2 * 2) + (0.2 * 4)
= 1.2 + 0.8 + 0.8 + 0.4 + 0.8
= 4
Sanfoundry Global Education & Learning Series – Machine Learning.
To practice all areas of Machine Learning, here is complete set of 1000+ Multiple Choice Questions and Answers.
If you find a mistake in question / option / answer, kindly take a screenshot and email to [email protected]
