This set of Data Mining Multiple Choice Questions & Answers (MCQs) focuses on “What Kind of Patterns can be Mined – Set 2”.
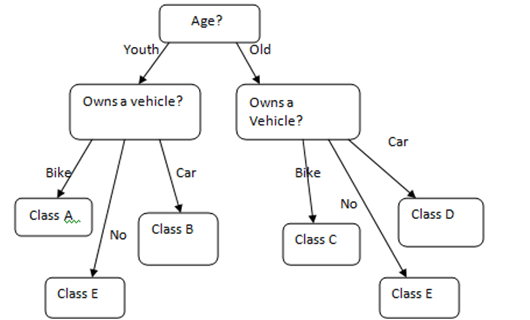
1. Given below is the diagram showing decision tree. What would be the class of a person who is 23 years old and owns a car?
a) Class A
b) Class B
c) Class C
d) Class D
View Answer
Explanation: The very first rectangle checks his age i.e. 25 and places him under the category of Young and the rectangle below the Youth arrow checks whether or not the person owns a Vehicle since he owns a car he is put in Class B.
2. Which among the following methods is not used for constructing a neural network?
a) Bayesian Classification
b) Support Vector Machines
c) Stemming Algorithms
d) K-nearest neighbor Classification
View Answer
Explanation: Stemming Algorithm is used to remove the unwanted letters which are not relevant for extracting the information from the database. A neural network is a collection of neuron like processing units with weighted connections between the units. Bayesian Classification, Support vector Machines, K-nearest neighbor Classification are the methods used for constructing neural networks.
3. Which values are generally modeled by Regression Analysis?
a) Continuous Valued Functions
b) Discrete Class Labels
c) Unordered Class Labels
d) Distorted Class Labels
View Answer
Explanation: Classification predicts categorical (discrete, unordered) labels, regression models continuous-valued functions. That is, regression is used to predict missing or unavailable numerical data values rather than (discrete) class labels.
4. Which among the given methods are preceded by Relevance Analysis?
a) Characterization and Discrimination
b) Association and Correlation
c) Classification and Regression
d) Clustering and Outlier Analysis
View Answer
Explanation: Classification and Regression may need to be preceded by relevance analysis, which attempts to identify attributes that are significantly relevant to the Classification and Regression process.
5. In which phase of data segregation is the clustering used?
a) Intermediate Phase
b) First Phase
c) Last Phase
d) Second Phase
View Answer
Explanation: Clustering analyzes data objects without consulting class labels. In many cases, class labeled data may simply not exist at the beginning. Clustering can be used to generate class labels for a group of data.
6. On which principles are the objects clustered or grouped?
a) Maximizing intraclass similarity
b) Minimizing intraclass similarity
c) Maximizing interclass similarity
d) Maximizing intraclass dissimilarity
View Answer
Explanation: The objects are clustered or grouped based on the principle of maximizing intraclass similarity and minimizing interclass similarity. Objects within the cluster have high similarity to the objects which are outside the cluster or another cluster.
7. Outliers are the objects that do comply with the general behavior of the Class/Model.
a) True
b) False
View Answer
Explanation: A data set may contain objects that do not comply with the general behavior or model of the data. These data objects are Outliers. Many data mining methods discard outliers as noise and exceptions, but these are interesting in some domains.
8. Can the outliers be detected from the cluster analysis?
a) Yes
b) No
View Answer
Explanation: Outliers may be detected using statistical tests that assume a distribution or probability model for the data, or using distance measures where objects that are remote from any other cluster are considered outliers.
9. Can the data mining generate all interesting patterns?
a) Yes
b) No
View Answer
Explanation: An ideal data mining system would generate all interesting patterns and only the interesting patterns. But the current data mining systems predict many other patterns along with the interesting ones and only the interesting ones.
10. Are all of the patterns generated by data mining system interesting?
a) Yes
b) No
View Answer
Explanation: The answer is no, only a small fraction of the patterns potentially generated would actually be of interest to a given user. And there are methods to predict whether or not a pattern generated is interesting. These measures are called interesting measures.
11. With what probabilistic measure can the Support measure be found for association rules of the form X ⇒Y ?
a) P(X U Y)
b) P(X ꓵ Y)
c) P (X|Y)
d) P (Y|X)
View Answer
Explanation: An objective measure for association rules of the form X ⇒Y is rule support, representing the percentage of transactions from a transaction database that the given rule satisfies. This is taken to be the probability P (X∪Y), where X∪Y indicates that a transaction contains both X and Y.
12. With what probabilistic measure can the Confidence measure be found for association rules of the form X ⇒Y ?
a) P(X U Y)
b) P(X ꓵ Y)
c) P (X|Y)
d) P (Y|X)
View Answer
Explanation: One of the objective measure for association rules is Confidence, which assesses the degree of certainty of the detected association. This is taken to be the conditional probability P(Y|X), that is, the probability that a transaction containing X also contains Y.
13. What are the objective interesting measures for Classification (If Then) rules?
a) Support and Confidence
b) Coverage and Confidence
c) Support and Accuracy
d) Accuracy and Coverage
View Answer
Explanation: The objective interesting measures for Association rules are Support and Confidence and the objective interesting measures for Classification (IF- Then) rules are Accuracy and Coverage.
14. Which among the following is not the interesting pattern as far the System perspective of the Interesting patterns are concerned?
a) Novel
b) Easily understood by Humans
c) Valid
d) Unexpected
View Answer
Explanation: A pattern is interesting as per the System Perspective if it is (1) easily understood by humans, (2) valid on new or test data with some degree of certainty, (3) potentially useful, and (4) novel.
15. Which among the following is not the interesting pattern as far the user perspective of the Interesting patterns are concerned?
a) Completeness
b) Actionable
c) Valid
d) Unexpected
View Answer
Explanation: These measures find patterns interesting if the patterns are unexpected (contradicting a user’s belief) or offer strategic information on which the user can act. In the latter case, such patterns are referred to as actionable. Patterns that are expected can be interesting if they validate on a hypothesis.
Sanfoundry Global Education & Learning Series – Data Mining.
To practice all areas of Data Mining, here is complete set of Multiple Choice Questions and Answers.
If you find a mistake in question / option / answer, kindly take a screenshot and email to [email protected]
