This set of Data Structures & Algorithms Multiple Choice Questions & Answers (MCQs) focuses on “Non-recursive Depth First Search”.
1. Which of the following data structure is used to implement DFS?
a) linked list
b) tree
c) stack
d) queue
View Answer
Explanation: Stack is used in the standard implementation of depth first search. It is used to store the elements which are to be explored.
2. Which of the following traversal in a binary tree is similar to depth first traversal?
a) level order
b) post order
c) pre order
d) in order
View Answer
Explanation: In DFS we keep on exploring as far as possible along each branch before backtracking. It terminates when all nodes are visited. So it is similar to pre order traversal in binary tree.
3. What will be the result of depth first traversal in the following tree?
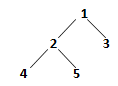
a) 4 2 5 1 3
b) 1 2 4 5 3
c) 4 5 2 3 1
d) 1 2 3 4 5
View Answer
Explanation: Depth first search is similar to pre order traversal in a tree. So here we will get the same result as for the pre order traversal (root,left right).
4. Which of the following is a possible result of depth first traversal of the given graph(consider 1 to be source element)?
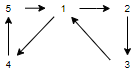
a) 1 2 3 4 5
b) 1 2 3 1 4 5
c) 1 4 5 3 2
d) 1 4 5 1 2 3
View Answer
Explanation: As 1 is the source element so it will be considered first. Then we start exploring the vertices which are connected to 1. So there will be two possible results-1 2 3 4 5 and 1 4 5 2 3.
5. Which of the following represent the correct pseudo code for non recursive DFS algorithm?
a)
procedure DFS-non_recursive(G,v): //let St be a stack St.push(v) while St is not empty v = St.pop() if v is not discovered: label v as discovered for all adjacent vertices of v do St.push(a) //a being the adjacent vertex
b)
procedure DFS-non_recursive(G,v): //let St be a stack St.pop() while St is not empty v = St.push(v) if v is not discovered: label v as discovered for all adjacent vertices of v do St.push(a) //a being the adjacent vertex
c)
procedure DFS-non_recursive(G,v): //let St be a stack St.push(v) while St is not empty v = St.pop() if v is not discovered: label v as discovered for all adjacent vertices of v do St.push(v)
d)
procedure DFS-non_recursive(G,v): //let St be a stack St.pop(v) while St is not empty v = St.pop() if v is not discovered: label v as discovered for all adjacent vertices of v do St.push(a) //a being the adjacent vertex
Explanation: In the iterative approach we first push the source node into the stack. If the node has not been visited then it is printed and marked as visited. Then the unvisited adjacent nodes are added to the stack. Then the same procedure is repeated for each node of the stack.
6. What will be the time complexity of the iterative depth first traversal code(V=no. of vertices E=no.of edges)?
a) O(V+E)
b) O(V)
c) O(E)
d) O(V*E)
View Answer
Explanation: As the time required to traverse a full graph is V+E so its worst case time complexity becomes O(V+E). The time complexity of iterative and recursive DFS are same.
7. Which of the following functions correctly represent iterative DFS?
a)
void DFS(int s) { vector<bool> discovered(V, true); stack<int> st; st.push(s); while (!st.empty()) { s = st.top(); st.pop(); if (!discovered[s]) { cout << s << " "; discovered[s] = true; } for (auto i = adjacent[s].begin(); i != adjacent[s].end(); ++i) if (!discovered[*i]) st.push(*i); } }
b)
void DFS(int s) { vector<bool> discovered(V, false); stack<int> st; st.push(s); while (!st.empty()) { s = st.top(); st.pop(); if (!discovered[s]) { cout << s << " "; discovered[s] = true; } for (auto i = adjacent[s].begin(); i != adjacent[s].end(); ++i) if (!discovered[*i]) st.push(*i); } }
c)
void DFS(int s) { vector<bool> discovered(V, false); stack<int> st; st.push(s); while (!st.empty()) { st.pop(); s = st.top(); if (!discovered[s]) { cout << s << " "; discovered[s] = true; } for (auto i = adjacent[s].begin(); i != adjacent[s].end(); ++i) if (!discovered[*i]) st.push(*i); } }
d)
void DFS(int s) { vector<bool> discovered(V, false); stack<int> st; st.push(s); while (!st.empty()) { s = st.top(); st.pop(); if (!discovered[s]) { cout << s << " "; discovered[s] = false; } for (auto i = adjacent[s].begin(); i != adjacent[s].end(); ++i) if (discovered[*i]) st.push(*i); } }
Explanation: In the correct version we first push the source node into the stack. If the node has not been visited then it is printed and marked as visited. Then the unvisited adjacent nodes are added to the stack. Then the same procedure is repeated for each node of the stack.
8. What is the space complexity of standard DFS(V: no. of vertices E: no. of edges)?
a) O(V+E)
b) O(V)
c) O(E)
d) O(V*E)
View Answer
Explanation: In the worst case the space complexity of DFS will be O(V) in the case when all the vertices are stored in stack. This space complexity is excluding the space required to store the graph.
9. Which of the following data structure is used to implement BFS?
a) linked list
b) tree
c) stack
d) queue
View Answer
Explanation: Queue is used in the standard implementation of breadth first search. It is used to store the vertices according to the code algorithm.
10. Choose the incorrect statement about DFS and BFS from the following?
a) BFS is equivalent to level order traversal in trees
b) DFS is equivalent to post order traversal in trees
c) DFS and BFS code has the same time complexity
d) BFS is implemented using queue
View Answer
Explanation: DFS is equivalent to pre order traversal in trees, not post order traversal. It is so because in DFS we keep on exploring as far as possible along each branch before backtracking. So it should be equivalent to pre order traversal.
Sanfoundry Global Education & Learning Series – Data Structures & Algorithms.
To practice all areas of Data Structures & Algorithms, here is complete set of 1000+ Multiple Choice Questions and Answers.
If you find a mistake in question / option / answer, kindly take a screenshot and email to [email protected]
- Practice Computer Science MCQs
- Check Programming Books
- Apply for Computer Science Internship
- Check Computer Science Books
- Practice Data Structure MCQ
